| Column 1 | Column 2 |
|---|---|
| Hallucination | Frequency of incorrect or irrelevant information produced by the VLM. |
| Temporal Context | How accurately the VLM maintains correct chronological relationships within the video. |
| Performance on Granular Queries | The VLM’s effectiveness in accurately responding to detailed and specific queries. |
| VideoDB Involvement | The extent to which VideoDB’s capabilities were leveraged to enhance VLM performance |
1. The Naive Gemini Approach
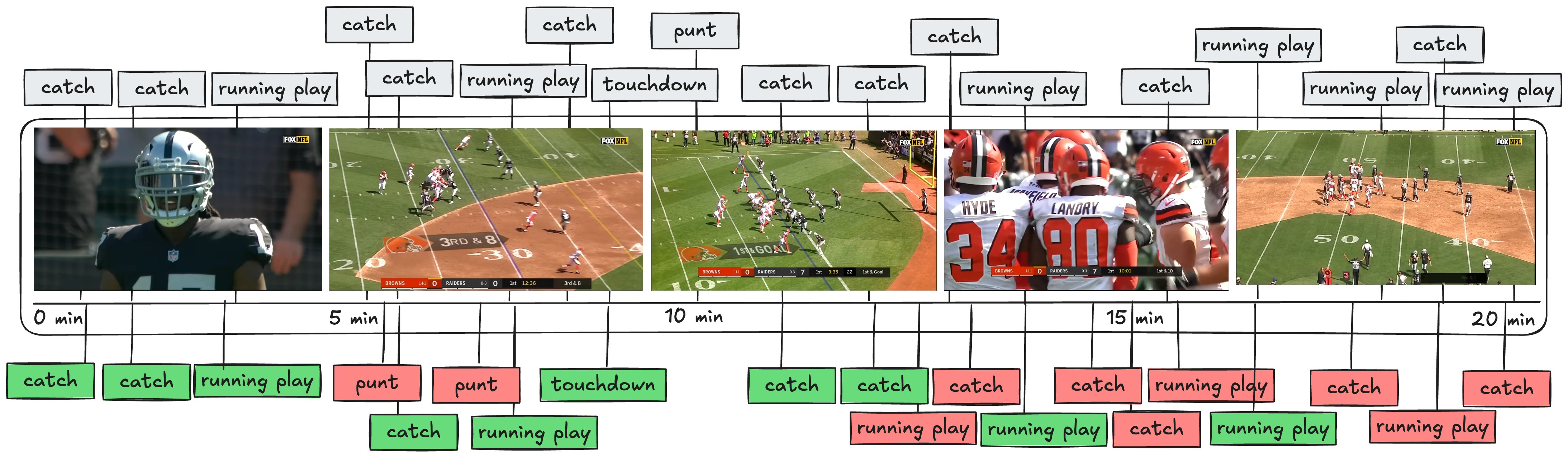
| Evaluation metric | Observation | Notes |
|---|---|---|
| Hallucination | 68.1 % | Frequent irrelevant predictions (68.1%). |
| Temporal Context | Bloated | Model often lost critical event continuity. |
| Performance on Granular Queries | Moderate | Struggled significantly. |
| VideoDB Involvement | Low |
- Finite context windows – even a 1 M-token window can’t hold one NFL quarter at 30 fps.
- Image-tile token explosion – every 1080p frame is split into ~4–9 tiles (≈ 1–4 k tokens) before the model “sees” it.
- Weak event reasoning – current VLMs reason per-frame, not per-play; they miss temporal causality (e.g., “Was the QB still behind the line when he released?”).
- Cost scales linearly with frames, so 30 fps steals wallets fast.
2. Uniform-Length Chunks (Possible with VideoDB)
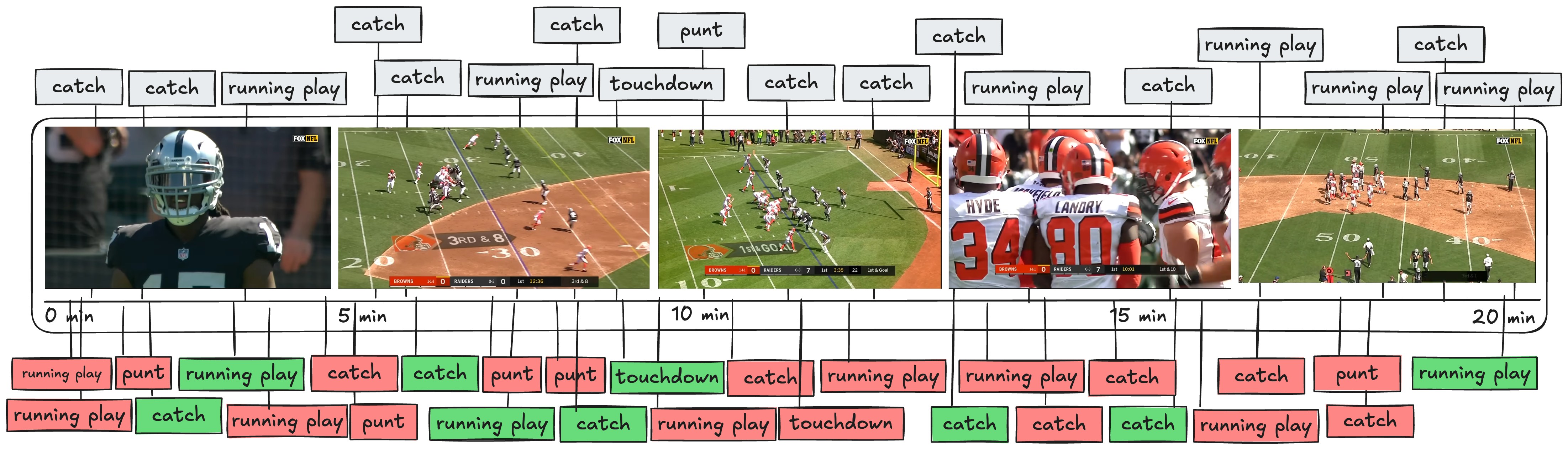
| Evaluation metric | Observation |
|---|---|
| Hallucination | 74.2 % |
| Temporal Context | Insufficient |
| Performance on Granular Queries | Moderate |
| VideoDB Involvement | Moderate |
- Important actions (e.g., QB throw) get split across two clips, so the model can’t see the full play and mis-judges legality or outcome.
- Same problem pops up for catches, interceptions, and other decisive moments.
- Model starts “imagining” passes and catches that never happened, simply because it lacks enough temporal evidence in a single clip.
- Resulting event timeline is noisy and bloated with false positives.
- Too long → information overload and confusion.
- Too short → not enough context.
- Neither extreme works; we need a balanced segmentation window.
3. Play-by-Play Segmentation (Advanced Pipeline with VideoDB)
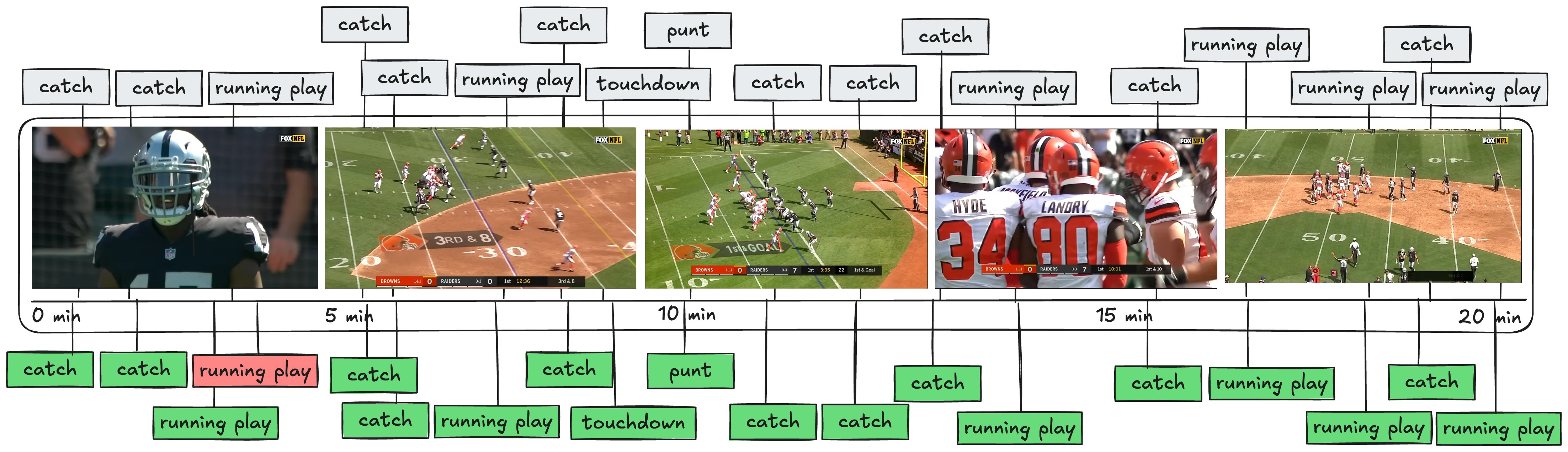
3.1 Aligning Game-Time with Video-Time
To solve this, we utilized the consistent visual feature found in all NFL broadcasts—the on-screen scoreboard. This scoreboard continuously displays vital game information, including scores, current quarter, down and yardage, and crucially, the game clock itself. By extracting this information, we could precisely map the game’s official timestamps to corresponding points in the video.How We Achieved This
- OCR-based Timestamp Extraction: We processed the video using an Optical Character Recognition (OCR) model to detect and extract visible game times from the scoreboard throughout the video.
- Frame Sampling Optimization: To optimize efficiency, we sampled just one frame per second (1 fps) for OCR processing. This significantly reduced computational load without compromising the accuracy of the extracted timestamps.
- Timestamp Mapping Creation: The OCR results provided an exact correlation between the official game timestamps and the actual runtime of the video. Using this mapping, we segmented the video accurately into individual play-by-play events.
Integrating Play-by-Play Segmentation with VideoDB
VideoDB effectively supports this customized, non-uniform segmentation approach. We imported our precise timestamp mappings directly into VideoDB, creating accurate and detailed scene indexes seamlessly:| Evaluation metric | Observation |
|---|---|
| Hallucination | 11.4% |
| Temporal Context | perfect |
| Performance on Granular Queries | High |
| VideoDB Involvement | High |
Approach Comparison
| Evaluation Metric | Naïve Whole-Video | Uniform Chunks | Play-by-Play |
|---|---|---|---|
| Hallucination | 68.1 % | 74.2 % | 11.4 % |
| Temporal Context | Poor | Insufficient | Perfect |
| Granular Queries | Moderate | Moderate | High |
| VideoDB Use | Low | Moderate | High |
Key Takeaways
-
Define Key Sports Concepts: Clearly outline and specify each concept required for analysis. For example:
- Catch (Yes/No)
- Running Play (Yes/No)
- Scoring Event (Yes/No)
-
Check Availability of Statistical Data: Determine if these concepts can be reliably extracted from existing statistical data:
- If statistical data is available: use it to isolate specific plays
- If statistical data is not available: directly use the Vision Language Model (VLM) for visual extraction
- Extract Relevant Plays Using Statistical Data: Use accurate statistical information to isolate relevant video scenes using VideoDB Timeline. Record timestamps and relevant metadata for these Scenes.
- Visual Analysis with VideoDB indexing: Pass the extracted scenes into the VLM to gather detailed visual insights (e.g., identifying catch types like “overhead” and positions like “near sidelines”).
- Clearly Structure the Output Data: Organize the extracted visual information into structured data for clarity and ease of querying. For instance:
- Query and Reasoning Engine (Small LLM): Upon receiving a user query, feed the structured data and query into VideoDB search interface. The engine processes these inputs and returns relevant, accurate play-by-play results.
Pricing: VideoDB vs. Gemini @ 1 fps
| 60-min NFL Game | Frames Analysed | VideoDB (Balanced tier) | Gemini 1.5 Pro* |
|---|---|---|---|
| 1 fps, 1080p | 3600 | **0.35 tokens | 7.4 |
| 5 fps | 18000 | $10.00 index | 37.0 |
| 30 fps | 108000 | $12.00 index | 220 |
Why Choose VideoDB
- Event-aligned indexing – cut by play, scene, or any custom timeline—not crude 1s slices
- Hybrid reasoning pipelines – blend stats, embeddings, and VLMs to slice hallucinations to ~11%
- Serverless scale – ingest petabytes or a single clip; zero idle cost
- Developer-first API – Python, JS, REST; one call for streams, one for scene queries
- Transparent pricing – pay once for storage + index; pick Entry / Advanced / SOTA LLM pricing per query
Explore the Docs
Learn more about the techniques and capabilities used in this case study:Visual Search Pipelines
Build sophisticated multi-modal search workflows
Scene Indexing
Segment and index video at semantic boundaries
Custom Annotations
Add domain-specific metadata to video content
Prompt Engineering
Optimize prompts for better VLM results