Quick Wins
- Use specific prompts during indexing
- Choose the right search type (semantic vs keyword)
- Tune thresholds based on your use case
- Combine multiple indexes for layered search
Understanding Precision and Recall
| Metric | Definition | Goal |
|---|---|---|
| Precision | % of returned results that are relevant | Fewer false positives |
| Recall | % of relevant content that was returned | Fewer missed results |
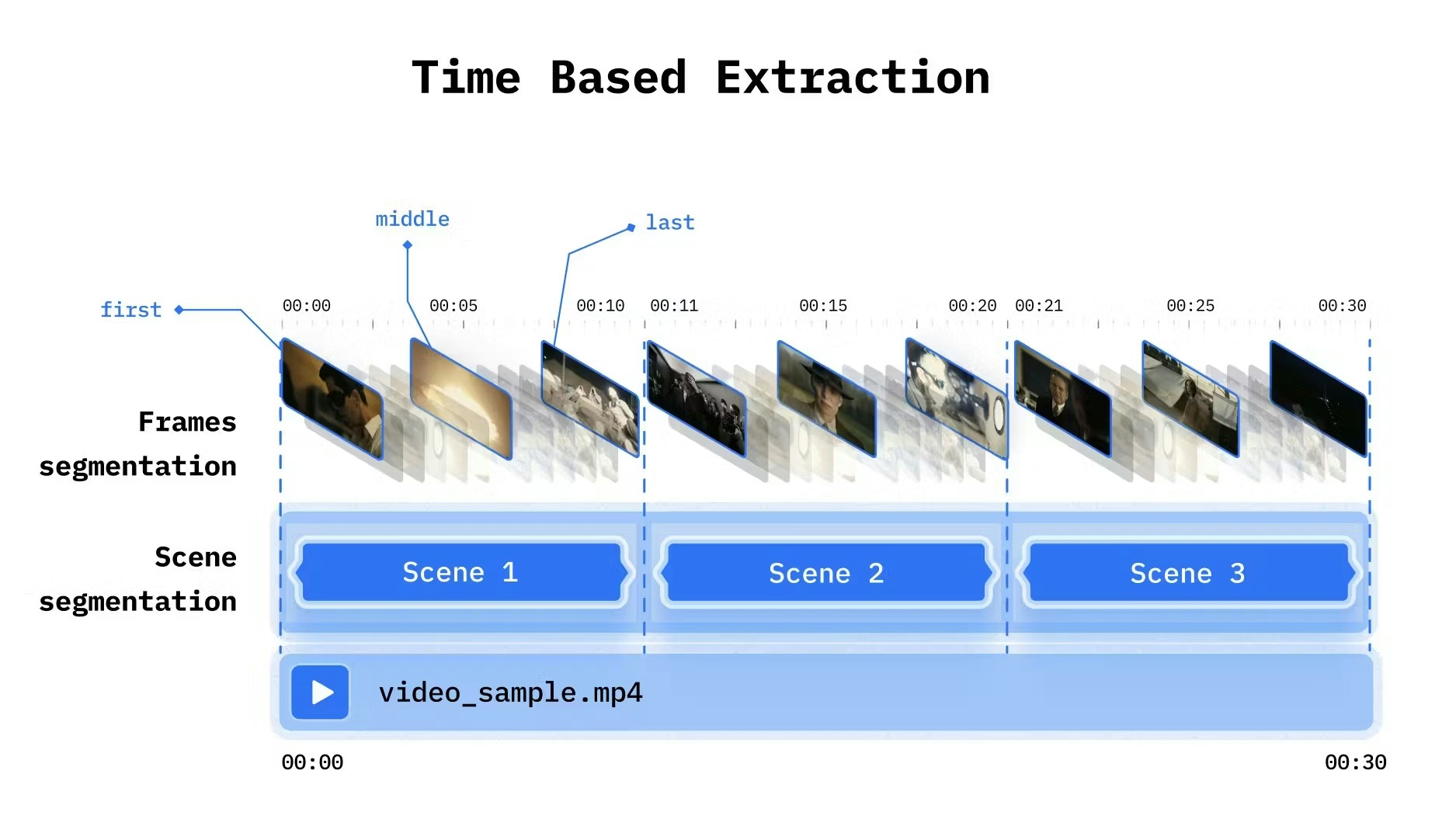
Indexing for Accuracy
Specific Prompts Beat Generic Ones
Match Extraction to Content Type
| Content | Extraction | Reasoning |
|---|---|---|
| Static shots | 1 frame/scene | Single frame captures all info |
| Action/motion | 3-5 frames/scene | Need temporal context |
| Quick cuts | Shot-based | Respect natural boundaries |
| Continuous | Time-based, short intervals | Capture changes |
Query Strategies
Semantic vs Keyword Search
| Query Type | Use Semantic | Use Keyword |
|---|---|---|
| Questions | ✓ “How does the engine work?” | |
| Concepts | ✓ “explains machine learning” | |
| Exact terms | ✓ “API” | |
| Technical names | ✓ “TensorFlow” | |
| Numbers | ✓ “2024” |
Threshold Tuning
| Parameter | Higher Value | Lower Value |
|---|---|---|
score_threshold | ↑ Precision, ↓ Recall | ↓ Precision, ↑ Recall |
result_threshold | More results | Fewer results |
dynamic_score_percentage | Stricter filtering | More inclusive |
Evaluating Search Quality
Set Up Ground Truth
Create test queries with known correct answers:Measure Precision and Recall
Advanced Techniques
Multi-Index Search
Layer indexes for precise filtering:Metadata Filtering
Pre-filter before semantic search:Post-Processing with LLMs
For complex queries, use an LLM to refine results:Common Pitfalls
| Problem | Cause | Fix |
|---|---|---|
| Missing relevant results | Threshold too high | Lower score_threshold |
| Too many irrelevant results | Threshold too low | Raise score_threshold |
| Semantic search misses exact terms | Wrong search type | Use keyword search |
| Poor visual search results | Generic prompt | Use specific, structured prompts |
| Inconsistent results | Wrong extraction config | Match extraction to content type |
Iterative Improvement
- Start broad - Low thresholds, high recall
- Evaluate - Check precision on sample queries
- Refine - Adjust thresholds, improve prompts
- Test - Validate against ground truth
- Repeat - Iterate until satisfied