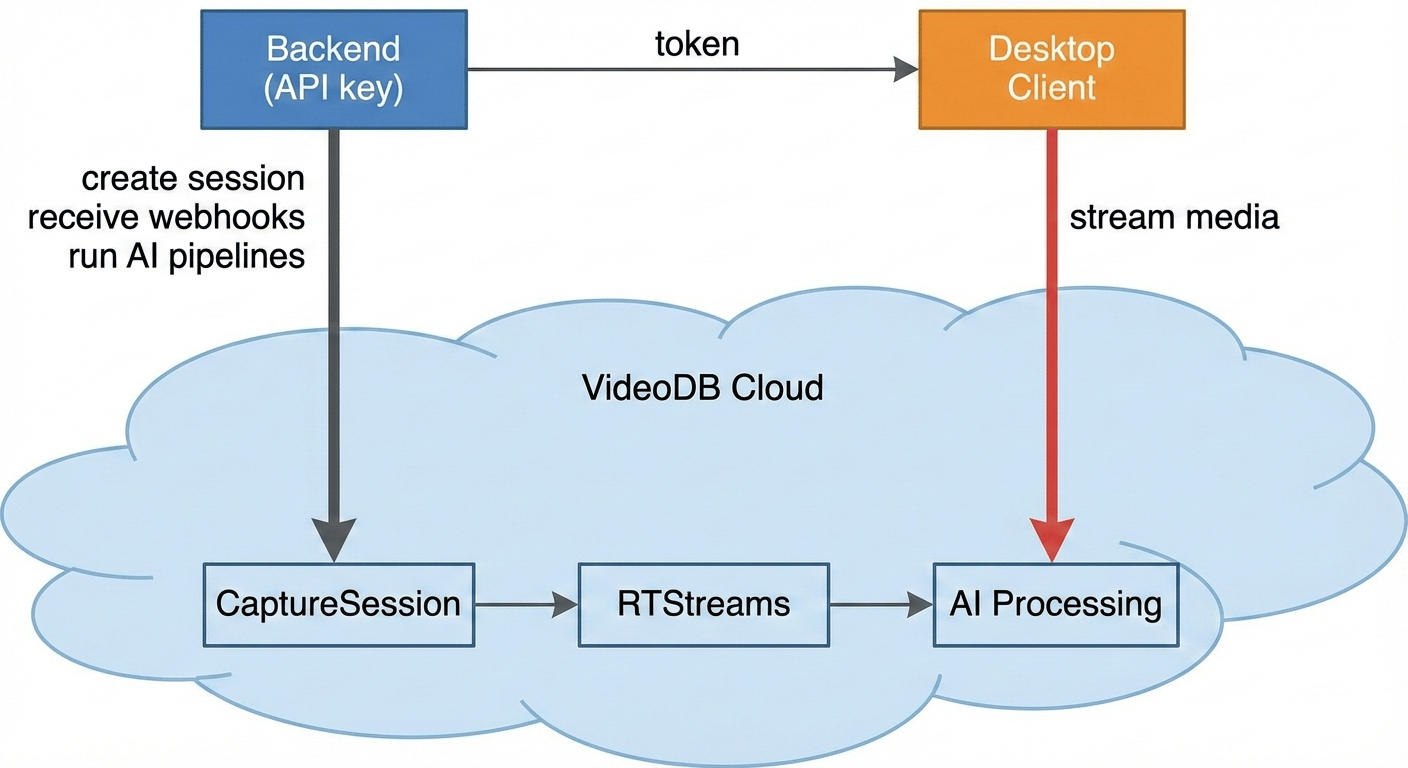
When capture begins, your backend receives a webhook and starts AI processing:
def on_webhook(payload: dict): if payload["event"] == "capture_session.active": cap_id = payload["capture_session_id"] cap = conn.get_capture_session(cap_id) # Get RTStreams (one per channel) mics = cap.get_rtstream("mic") displays = cap.get_rtstream("display") # Start real-time AI processing if mics: mic = mics[0] mic.start_transcript() mic.index_audio(prompt="Extract key decisions and action items") if displays: display = displays[0] display.index_visuals(prompt="Describe what the user is doing")
The lifecycle container for one capture run. Created by backend, activated by desktop client.States:created → starting → active → stopping → stopped → exported
A real-time media stream, one per captured channel. This is where you run AI:
rtstream.start_transcript()rtstream.index_audio(prompt="Extract key decisions")rtstream.index_visuals(prompt="Describe what user is doing")rtstream.search("budget discussion")
When multiple monitors are connected, each appears as a separate display:N channel. Use cap.displays on the backend to inspect available video channels:
Python
cap = conn.get_capture_session("cap-xxx")# List all video (display) channelsfor d in cap.displays: print(f"{d.channel_id} primary={d.is_primary}")# display:1 primary=True# display:2 primary=False
cap.displays returns a list of video channel objects. Each object includes an is_primary field that indicates which display was set as the primary video channel when capture started (via primary_video_channel_id).To capture multiple screens, pass all desired display channels to the desktop client:
Each display produces its own RTStream on the backend. The primary display is used for the default muxed export video; non-primary displays are available as raw channel assets or can be exported separately (see Storage & Search).