Quick Example
Lifecycle Control
Start/Stop
Status Values
| Status | Description |
|---|---|
connected | Actively ingesting |
stopped | Paused, can resume |
error | Connection issue |
Export a Stopped Stream
After stopping a stream, you can export it as a video or audio asset in your collection usingexport().
Export Parameters
| Parameter | Type | Description |
|---|---|---|
name | str (optional) | Name for the exported asset. Defaults to "{stream_name} - Recording" |
RTStreamExportResult
| Attribute | Description |
|---|---|
video_id | The ID of the exported video/audio asset |
stream_url | HLS stream URL for playback |
player_url | Shareable player URL (None for audio-only channels) |
name | Name of the exported asset |
duration | Duration of the recording in seconds |
Index Lifecycle
Indexes can also be started/stopped independently:Meeting Recording
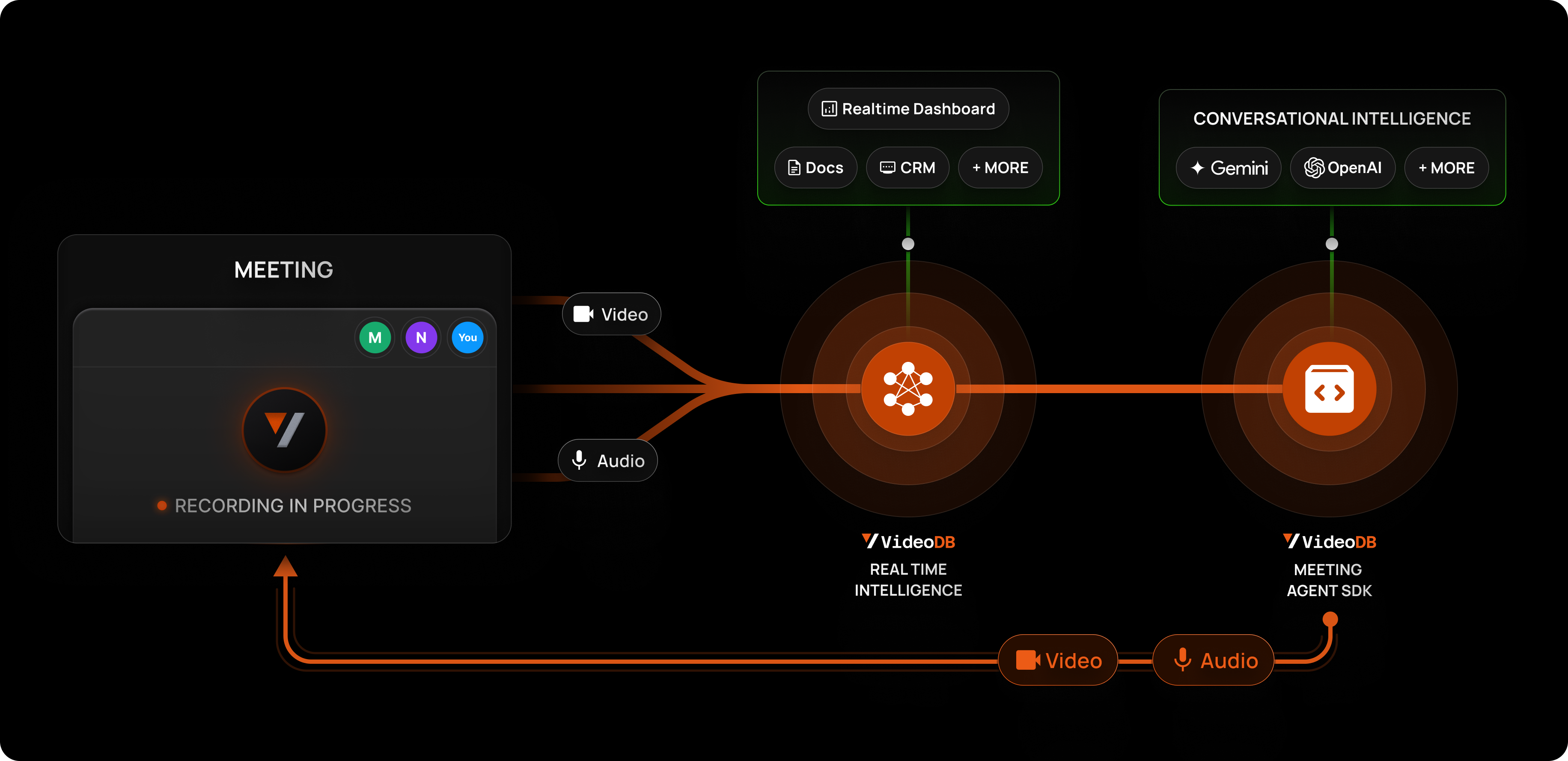
Record from Zoom, Google Meet, or Microsoft Teams. A bot joins your meeting, records, and uploads directly to VideoDB.
Start Recording
Recording to Collection
Track Recording Status
Recording Status Values
| Status | Description |
|---|---|
initializing | Bot is being set up |
processing | Actively recording |
done | Recording complete |
failed | Recording failed |
Callback Payload
Success:Access Recording
Supported Platforms
| Platform | URL Format |
|---|---|
| Google Meet | https://meet.google.com/xxx-xxxx-xxx |
| Zoom | https://zoom.us/j/123456789 |
| Microsoft Teams | Teams meeting link |
Meeting Features
- Brand-able Bot - Custom name and avatar
- Speaker Timeline - Per-speaker timestamps (Google Meet)
- Webhook Callbacks - Get notified on completion
- Collection Storage - Video lands directly in your collection
Next Steps
RTSP Ingest
Connect camera streams
Real-time APIs
Index and search live streams